Introduction
It would be cool to find a 2D character’s source anime by using her/his images. Some platforms may use this system to help users find animes. Others may use it to check whether one’s newly created character already has his/her debut, i.e., the new character is not original enough.
One solution is to rely on Google Image’s Image Search, also called reverse image search, which can find similar images and their sources indexed by Google. However, it fails to provide the right source when the input image is an original one.
It’s due to the nature of its encoding and indexing method. First, when Google makes embeddings (vectors) for images to find their similar counterparts, I think they will use a general algorithm that fits typical pictures’ traits. However, anime pictures and sketches don’t belong to this group. Thus, this kind of image embeddings doesn’t have the necessary information to represent their semantics. Second, thanks to the emphasis on speed, Google will not use a machine learning model to predict one image’s identity from the embedding. Instead, to the best, they will use distance rules to find other images whose embeddings are close to the input’s embedding. A typical software using distance is Facebook’s faiss. This system has excellent speed performance. However, because it relies on distance computations, such as L2 distance or cos distance, the manipulation it can conduct on the embeddings is limited, which results in a sub-optimal search result. Or, if they think the distance system will still hurt the performance, they would simply use input metadata to match other images.
To better meet the demand, we need to make a system that specialized to encode anime characters’ head images and uses machines learning to predict the classes. We use heads instead of the full images because, in this way, we can improve its generalization and performance. The background and cloth information is indeed essential to identify a character. However, in our application, the input may only have head information. It’s critical to let the model’s training data match the future inputs as close as possible to reduce the training/serving skew.
Also, the computation for the embedding is lighter when the input is the head part than it’s the full picture, which can boost the system’s speed performance. There are a few methods close to this expectation, like Moeflow, but it only supports 100 characters with an accuracy of 70% (unknown whether it is top-N or first-1-precision).
Main Problems
- How to detect characters’ heads from images
- How to extract semantic embeddings from heads
- How to make probability predictions from an embedding
Solutions I applied
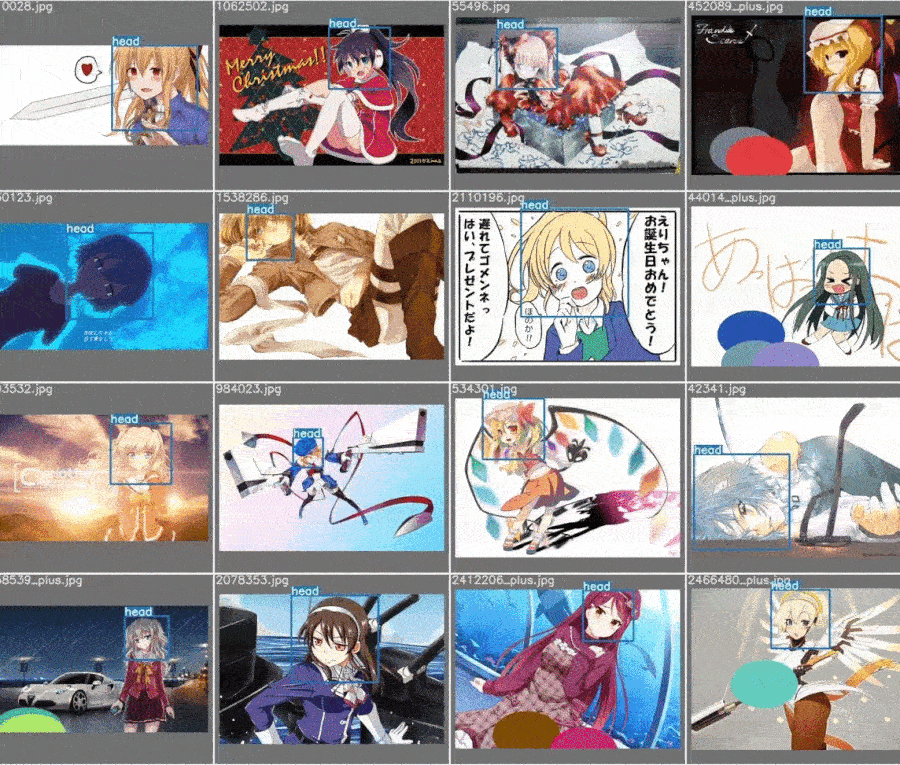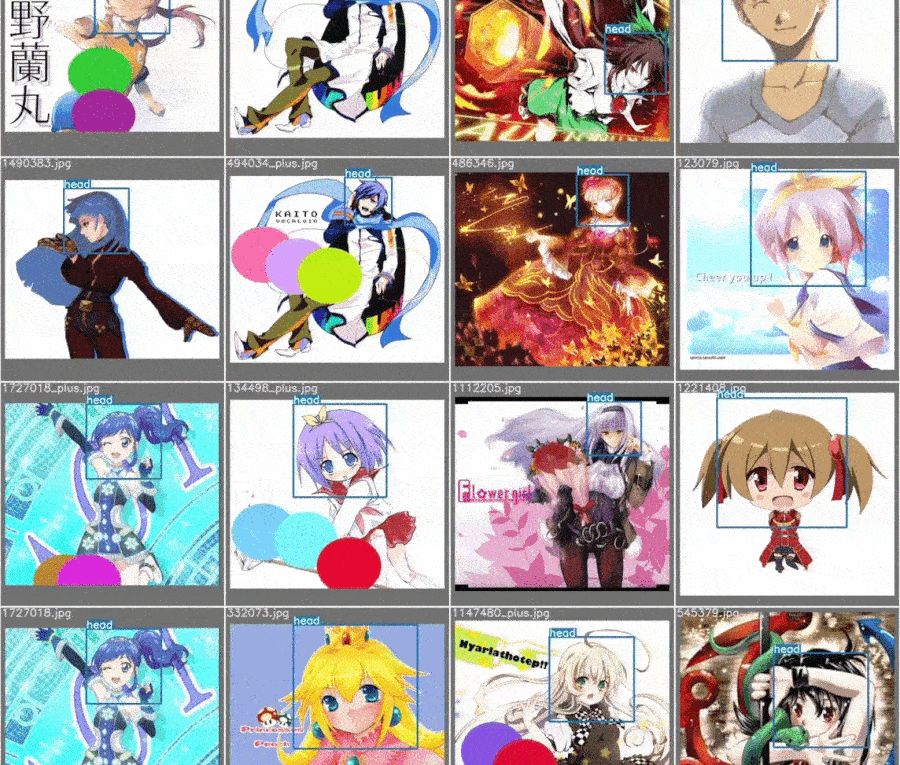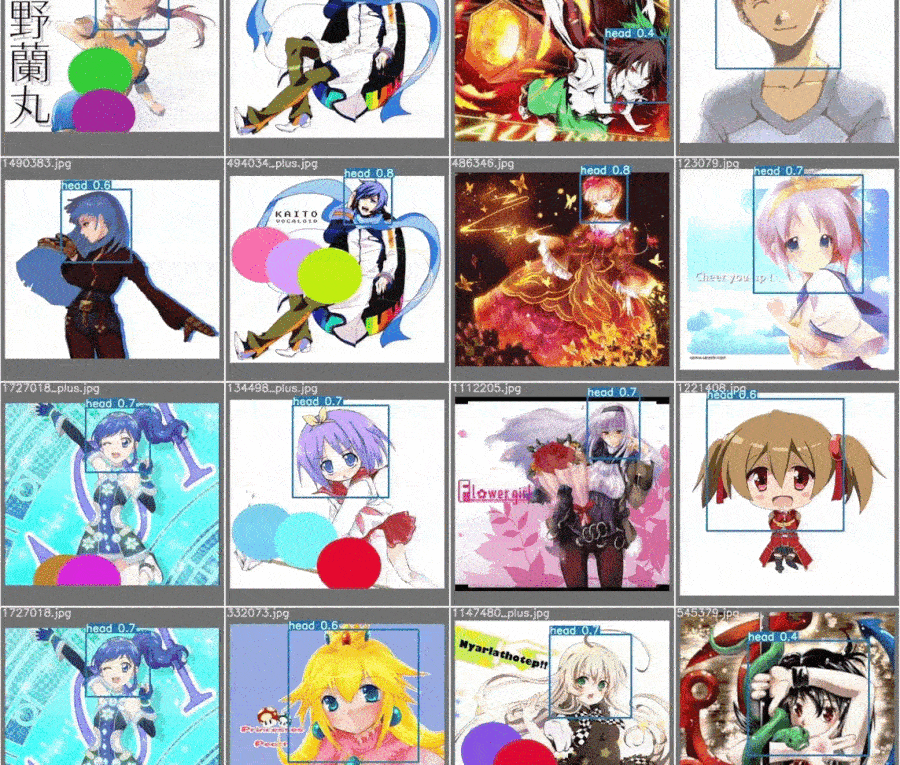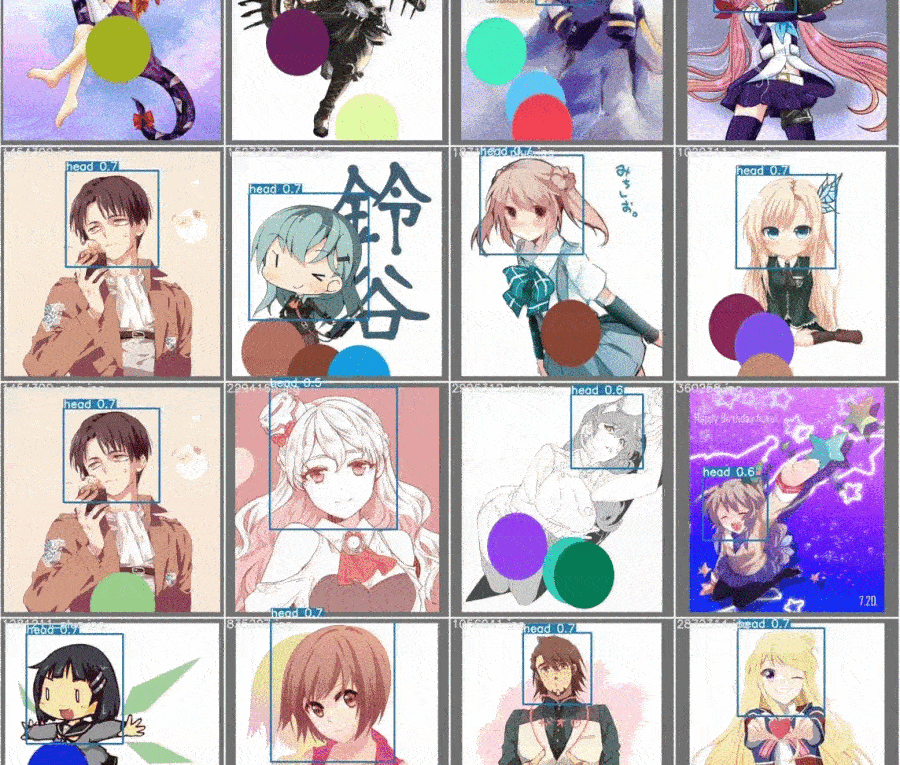
YOLO, for head detection
There are trained models for face detection, like AniSeg or animeface-2009 and AnimeHeadDetector. The reasons why we didn’t use them are:
- They are a little bit out of date, considering the state-of-art;
- More importantly, they detect faces instead of head, except AnimeHeadDetector.
Since this’s a project for fun, why not try something new.
YOLO is an excellent system for object detection. Officially, the latest version publishes is [V4]. But, I have to admit the training method showing in their Github is too chaotic. Because this’s a project for fun (again), why not use another user-friendly framework yolov5. It’s not an authentical YOLO version. However, the performance is still decent, and its customed training method is pretty clean.
Here, I used the predicted label from the previous model and made changes so that the label box cover the whole head. To avoid the model only learn oval/ellipse contours to detect head, we added 1-3 randomly colored circles to training images.
def add_sphere(im: Image, xmin, ymin, xmax, ymax):
draw_time = random.randint(1, 3)
for _ in range(draw_time):
draw_random_sphere(im, xmin, ymin, xmax, ymax)
Metric learning, for embedding extraction
To enable the search of images based on conceptually similar features from the query, we need a similarity function that can measure how similar these different representations are, i.e., the distances among them.
Studies have shown that metric learning, which automatically constructs task-specific distance metrics from supervised or weakly supervised data in a machine learning manner, performs well in solving this problem, such as face recognition. It uses ranking losses, such as pairwise ranking loss
and triplet ranking loss, to “learn” how to produce similar representations for similar inputs and distant representations for the different inputs.
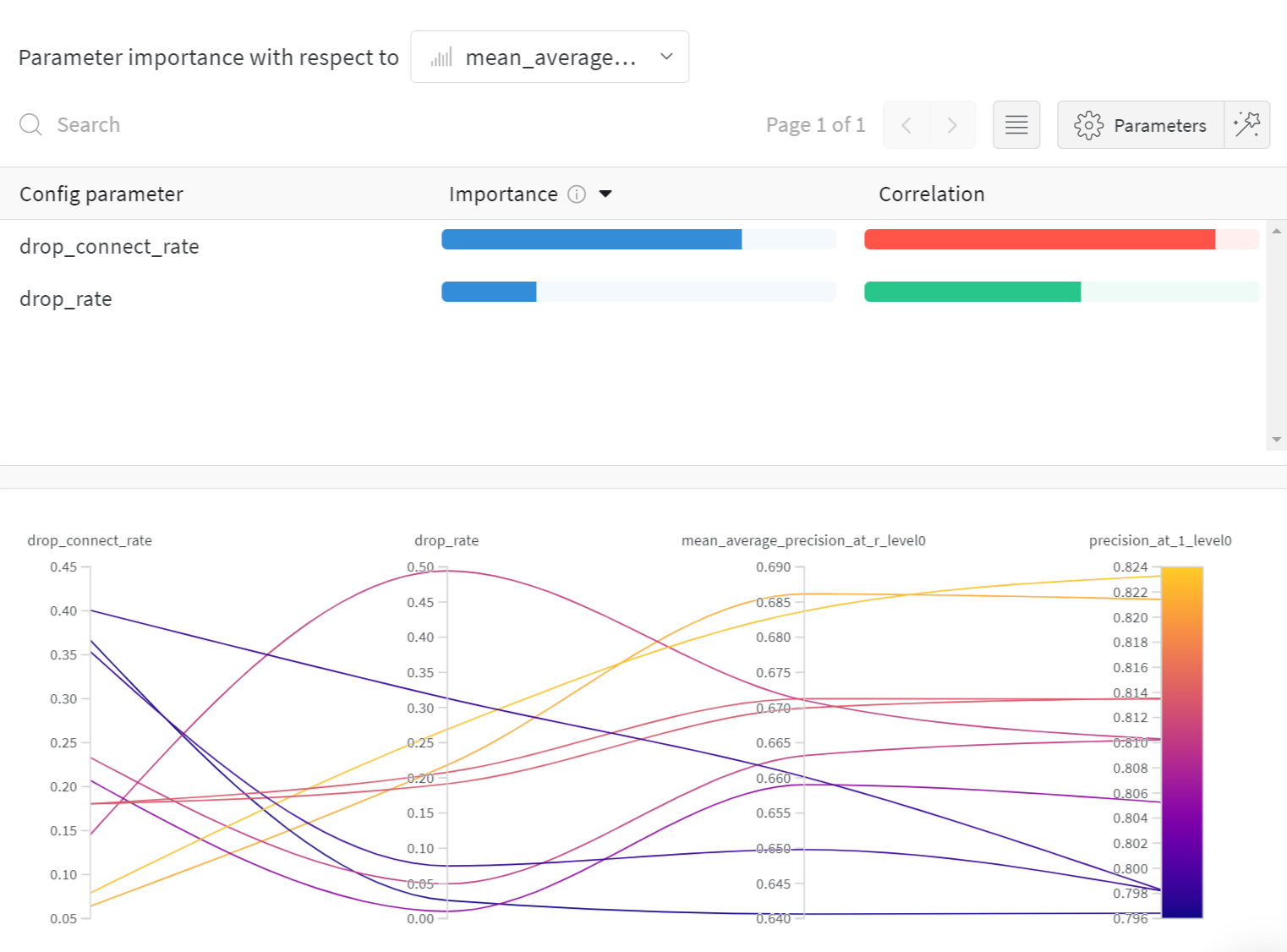
Here, we used the incredible library PyTorch Metric Learning to conduct the training process. From the paper, we learned MultiSimilarityLoss is one of the best loss functions for this task, and its parameters are simple, so we chose it as the loss function. We also followed the recommendation in that paper to use Mean Average Precision at R (MAP@R), which combines the ideas of Mean Average Precision and R-precision as the primary metrics.
We used the data from Danbooru 2018 Anime Character Recognition Dataset. We randomly selected 45 images from the characters with more than 50 images, which results in 1551 characters and 67,545 images. The backbone MixNet-S is created by using the library, EfficientNets for PyTorch , which provides pre-trained models and corresponding export methods. Since two hyperparameters can be tuned, we used wandb sweep to assist the process. With its built-in support for Parameter importance and Bayesian optimization, it’s comfortable to compare experiments and tune the hyperparameters without writing custom code.
Perceptron, for classification
A single-layer neural network represents the most simple neural network form, and it has a fancy name, Perceptron.
Here, since the embeddings are optimized to distinguish one character’s head from that of another, a perceptron should be strong enough to handle the classification. We also made a classifier based on faiss and use the neighborhood to make predictions. We compared the top-5 precision of the two models and found Perceptron performs better. We also tested some traditional machine learning models, such as LinearSVC(slow training), KNeighborsClassifier(model size too large), [RandomForestClassifier](too slow training) and NearestCentroid(inferior performance).
We also a pipeline form *making embeddings” to *compare Perceptron and faiss* using MLflow. To be honest, it’s not mature enough yet. And it’s complicated to build a pipeline using MLflow. A glance at the pipeline would be like the following.
_get_or_run(
"train",
{
"train_dir": train_dir,
"val_dir": val_dir,
"epochs": epochs,
"drop_rate": drop_rate,
"drop_connect_rate": drop_connect_rate,
},
git_commit,
use_cache=False,
)
...
_get_or_run(
"export",
{"model_path": model_path, "out_path": data_dir / "faceEncoder.onnx"},
git_commit,
use_cache=False,
)
_get_or_run(
"embed",
{
"model_path": model_path,
"out_path": data_dir,
"dataset_path": embed_dataset_path,
},
git_commit,
use_cache=False,
)
Results
Datasets
- Anime character head labelled dataset for YOLO training
- 815 anime character head dataset with more than 99 heads per character for embedder training
- 1551 anime character head dataset with 45 heads per character for each for classifier training
Crystal Eyes
This system’s advantage is that the recognition doesn’t rely on indexing, making it lightweight and enabling it to recognize unseen images.
To our knowledge, Crystal Eyes is the first system that can recognize more than 1500 2D characters with high performance using machine learning.
With 25 images’ embeddings as training data and 20 images’ embeddings as test data for each character, the classifier can achieve 0.860 top-3 accuracy and 0.892 top-5 accuracy.
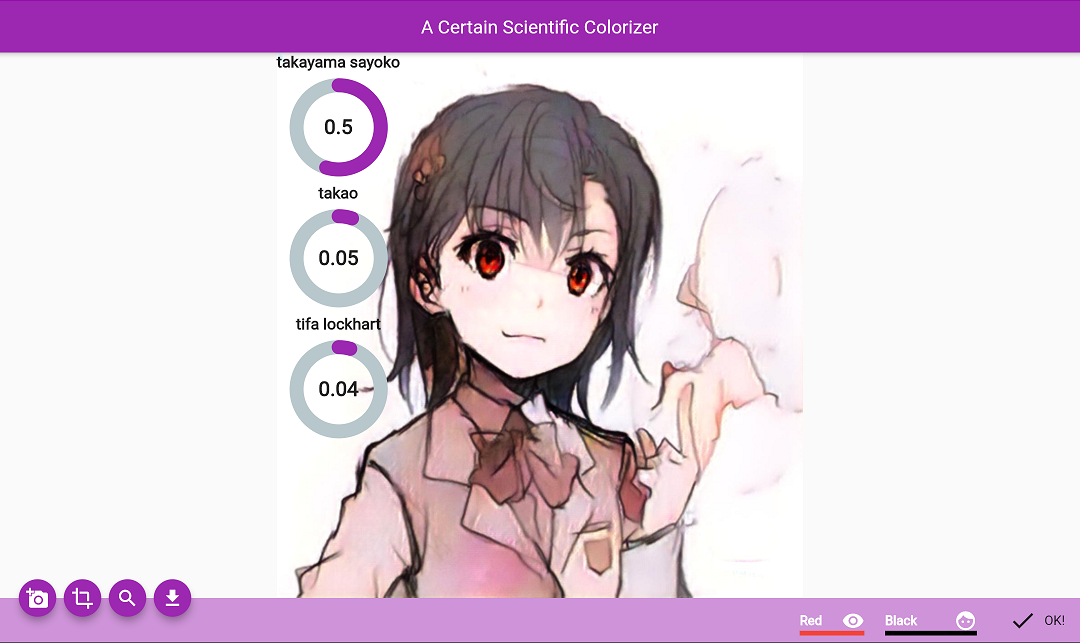
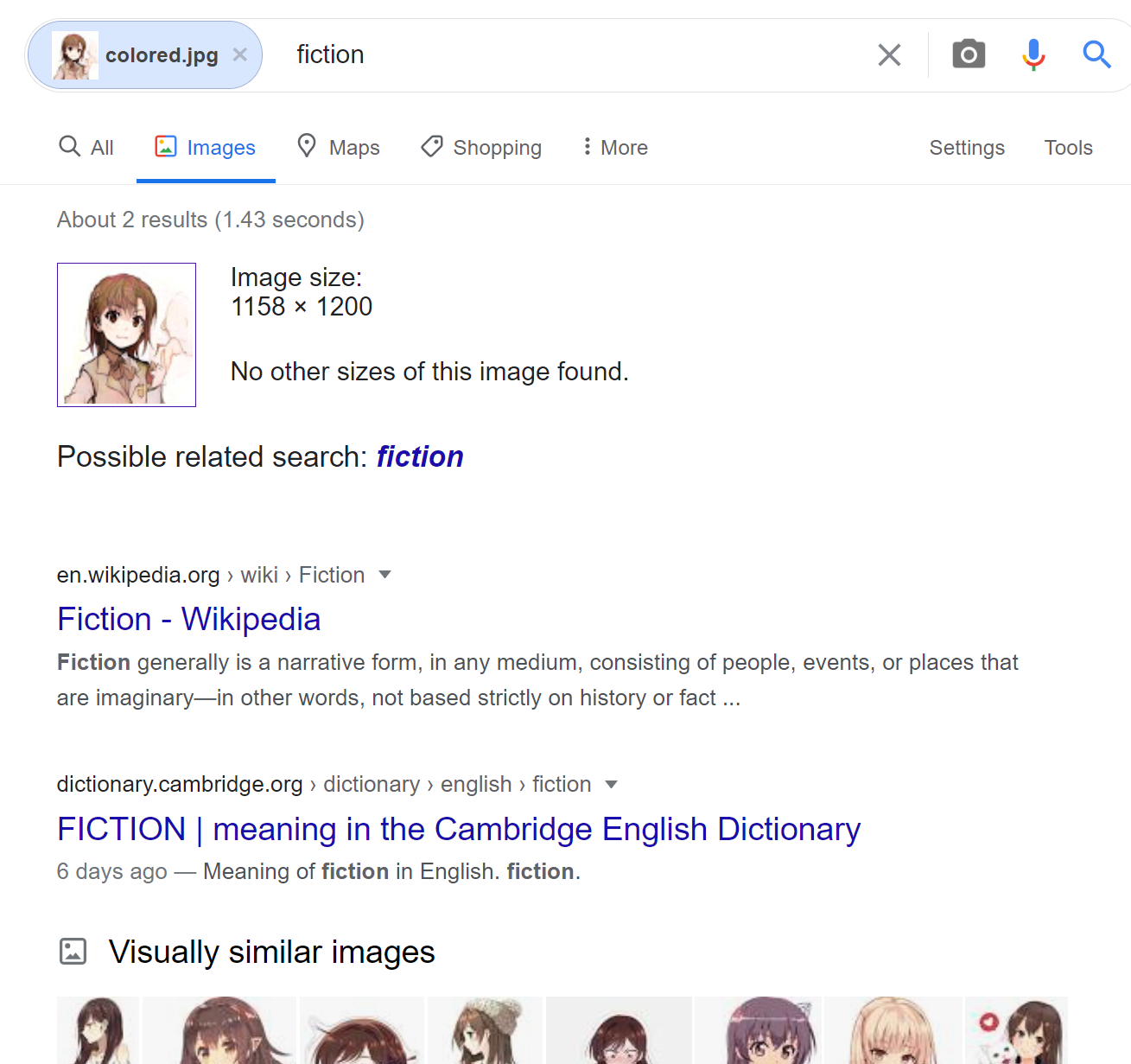
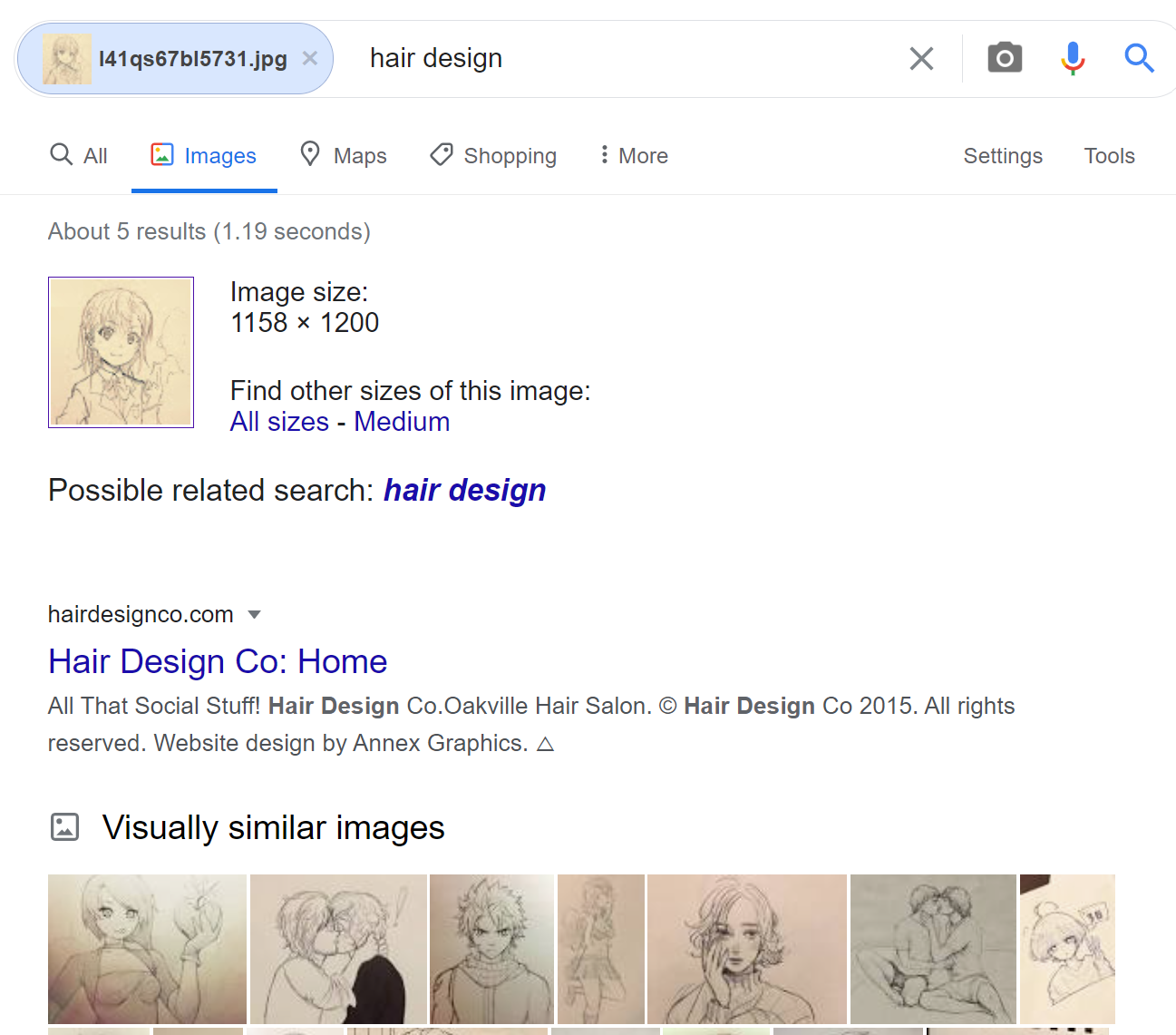
It can recognize colored 2D characters and their sketches but with low confidence. We used the samples Google failed at before as examples.

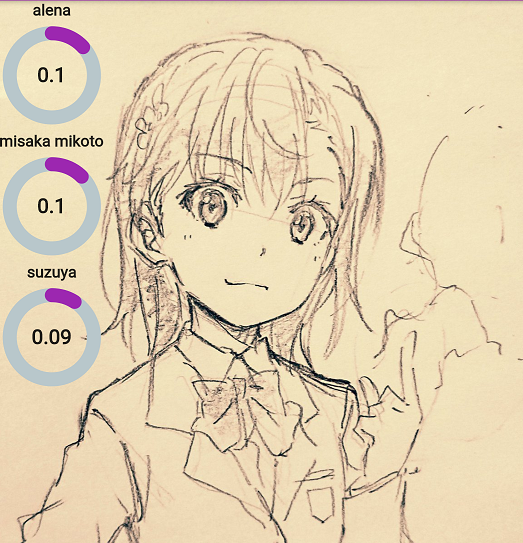
Here, we show a possible application for the system, that is, to tell the user whether the character newly designed is original enough.
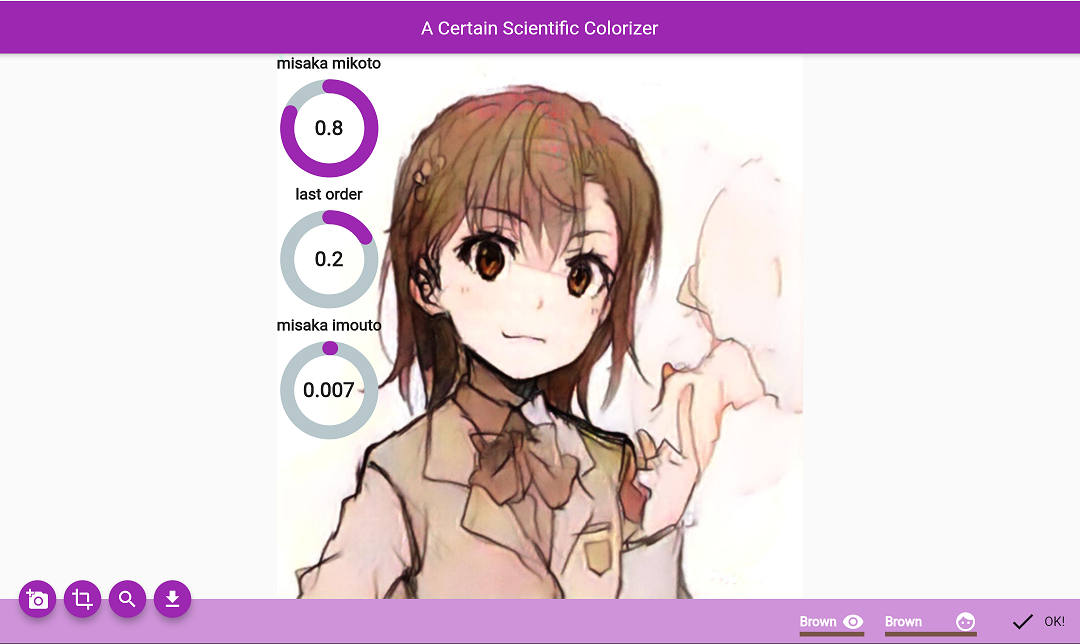
Right! This face with brown hair and brown eyes is too similar to Misaka, the protagonist in A Certain Scientific Railgun (actually, it’s Misaka’s sketch colored by Colorizer, a GAN system using Tag2Pix). But if we colored the hair with black hair and red eyes, it may turn out to be an original character (just kidding).